
How to Implement Machine Learning in Manufacturing: A Practical Guide for Production Teams
How to Implement Machine Learning in Manufacturing: A Practical Guide for Production Teams
The question comes up constantly in manufacturing boardrooms: how do you implement machine learning in your production without disruption? The intuitive answer — hire a data scientist and rebuild your data infrastructure — discourages most production directors before a single pilot has been launched. That answer is wrong. Here is the practical guide for deploying ML on your existing lines.
Implementing machine learning in manufacturing: three essential prerequisites
1. Accessible historical data
ML needs data to learn. In most factories, that data already exists: process historians, SCADA systems, IoT sensors, CSV exports. The question is not whether you have data — you do — but whether it is extractable in a standard format (CSV, API, live feed).
2. A defined target variable
What problem do you want to solve first? Reduce downtime on a critical line? Improve the yield of a specific process? ML performs best when the objective is precise. Start with a costly, measurable problem and at least 3 months of historical data.
3. Operator involvement
The highest-performing ML models incorporate operator knowledge. Your shop floor team knows intuitively which parameters affect their process quality. Involve them from the variable selection phase — their domain expertise makes the difference between a model that works in theory and one that works in practice.
Four steps to implement machine learning in your manufacturing production
Step A — Data connection (weeks 1-2)
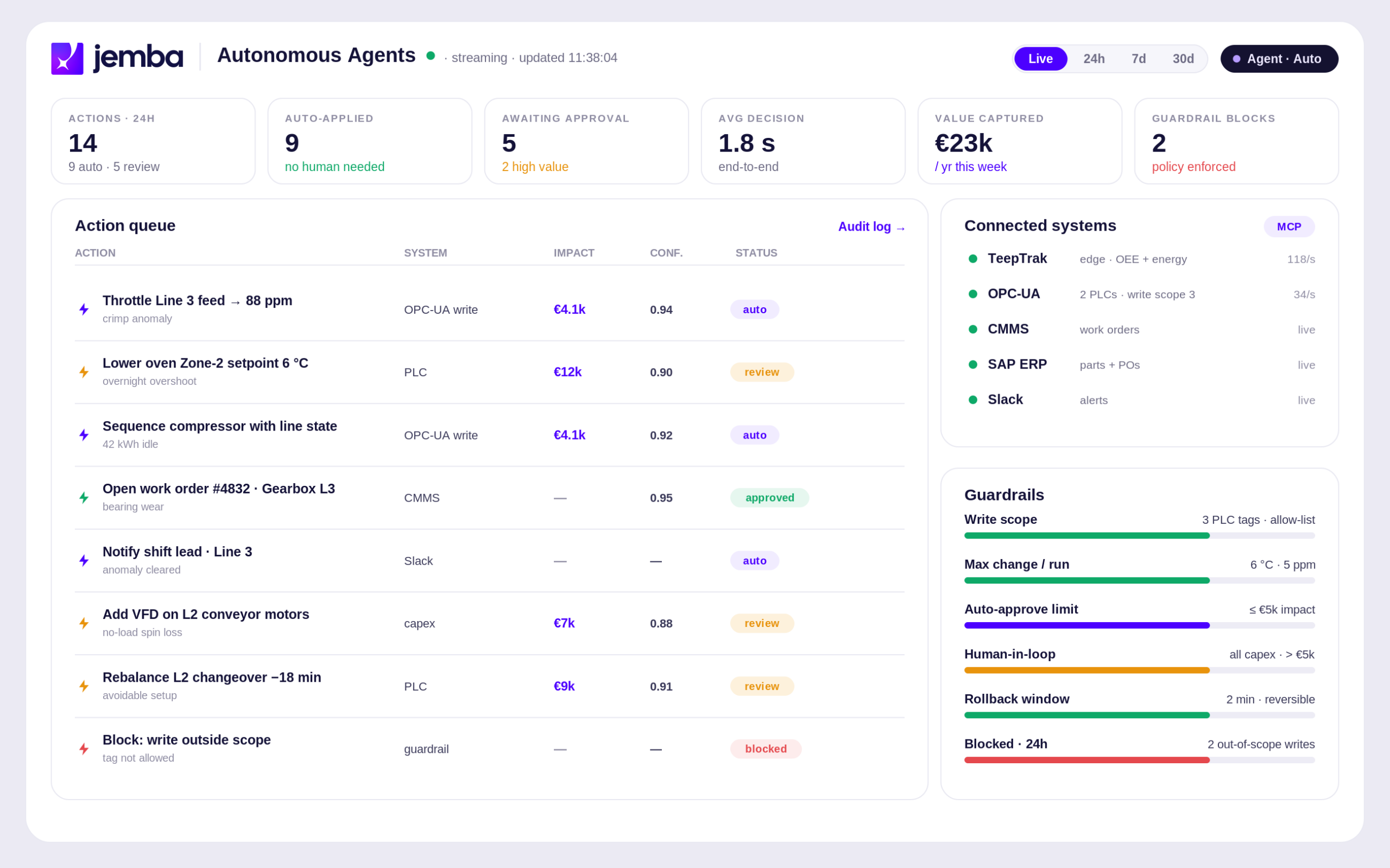
Connect your data source to the ML platform: CSV import from your historian, API connection to your SCADA, or live feed via TeepTrak IoT sensors. No IT development is required — the connection is configured in a few hours by your process team.
Step B — ML project creation (weeks 2-3)
Define your target variable and the parameters to analyse. The platform guides you through algorithm selection for your specific use case. No code, no mathematics — a configuration interface accessible to everyone.
Step C — Automatic training (week 3-4)
The ML model trains automatically on your historical data. This step is fully automated. The platform selects optimal hyperparameters, validates the model on a test partition of your data, and presents performance metrics in plain language.
Step D — Results and continuous improvement (from week 4)
Your model is live in production. Alerts reach your operators dashboards in real time. Recommendations are formulated in clear language, without technical jargon. Your teams act. The model improves continuously as it accumulates new data.
Five common mistakes in industrial ML implementation
- Starting too big — One pilot, one line, one precise use case. Do not deploy ML across the entire factory in a single phase.
- Neglecting data quality — Missing or poorly timestamped data produces unreliable models. Clean before training.
- Waiting for a data scientist — Modern ML platforms no longer need one. That hiring process unnecessarily extends time-to-value by 6 to 12 months.
- Ignoring operators — An ML model your operators do not understand will be bypassed. Involve them in alert validation from day one.
- Not measuring ROI upfront — Define your KPIs before deployment: cost of an unplanned stop, current scrap rate, energy cost per unit.
What data do I need to implement ML in my production?
Industrial ML works with the data you already have:
- Sensor data: temperature, pressure, vibration, flow rate, electrical consumption
- Process data: line speed, setup parameters, production recipes
- Quality data: inspection results, scrap rates, non-conformance codes
- Production data: cycle times, OEE, downtime by cause
Jemba accepts all these sources via CSV, REST API, or direct TeepTrak feed. The platform automatically handles data cleaning, time alignment and normalisation. See how on the Jemba platform page.
How long does it take to implement machine learning in manufacturing?
- First insights: 4 weeks after data connection
- Model live on one line: 6 to 8 weeks
- Multi-line deployment: 18 weeks on average
- Positive ROI: from year 1 (2.7 times on average)
These timelines are achievable without new hires, without infrastructure changes, and without immobilising your IT team for months. The documented case studies detail these results with real figures.
See Jemba on your own data
A 30-minute session with a product specialist. No data scientist required, 48-hour setup.