
Comment Intégrer le Machine Learning dans sa Chaîne de Production Industrielle
Comment Intégrer le Machine Learning dans sa Chaîne de Production Industrielle
La question revient systématiquement dans les comités de direction industriels : comment intégrer le machine learning dans sa production sans disruption ? La réponse intuitive — recruter un data scientist et refaire son infrastructure data — décourage la majorité des directeurs industriels avant même d’avoir lancé un projet pilote. Cette réponse est pourtant fausse. Voici le guide pratique pour déployer le ML sur vos lignes existantes.
Intégrer le machine learning en production : les 3 prérequis fondamentaux
1. Des données historiques accessibles
Le ML a besoin de données pour apprendre. Dans la plupart des usines, ces données existent déjà : historiens de process, SCADA, capteurs IoT, fichiers CSV. La question n’est pas de savoir si vous avez des données — vous en avez — mais de vérifier qu’elles sont extractibles dans un format standard.
2. Une variable cible définie
Quel problème voulez-vous résoudre en premier ? Réduire les arrêts sur une ligne critique ? Améliorer le rendement d’un process ? Le ML fonctionne mieux quand l’objectif est précis. Commencez par un problème coûteux et mesurable, avec au moins 3 mois d’historique.
3. L’implication des opérateurs terrain
Les modèles ML les plus performants intègrent la connaissance des opérateurs — qui savent quels paramètres influencent la qualité de leur process. Associez-les dès la phase de sélection des variables.
Les 4 étapes pour intégrer le machine learning dans votre production
Étape A — Connexion des données (semaines 1-2)
Connectez votre source de données à la plateforme ML : import CSV depuis votre historien, connexion API à votre SCADA, ou flux temps réel via les capteurs IoT TeepTrak. Aucun développement informatique n’est nécessaire — la connexion est configurée en quelques heures.
Étape B — Création du projet ML (semaines 2-3)
Définissez votre variable cible et les paramètres à analyser. La plateforme vous guide dans la sélection des algorithmes les plus adaptés à votre cas d’usage. Pas de code, pas de mathématiques — une interface accessible à tous.
Étape C — Entraînement automatique (semaine 3-4)
Le modèle ML s’entraîne automatiquement sur votre historique. La plateforme sélectionne les hyperparamètres optimaux, valide le modèle et vous présente les métriques de performance.
Étape D — Résultats et optimisation continue (à partir de la semaine 4)
Votre modèle est en production. Les alertes arrivent en temps réel sur le tableau de bord de vos opérateurs. Les recommandations sont formulées en langage clair, sans jargon technique.
Les 5 erreurs les plus fréquentes dans l’intégration du ML industriel
- Commencer trop grand — Un pilote sur une ligne, un cas d’usage précis. Ne déployez pas sur toute l’usine en une seule fois.
- Négliger la qualité des données — Des données manquantes ou mal horodatées produisent des modèles peu fiables. Nettoyez avant d’entraîner.
- Attendre un data scientist — Les plateformes ML modernes n’en ont plus besoin. Ce recrutement allonge inutilement le time-to-value de 6 à 12 mois.
- Ignorer les opérateurs — Un modèle ML que les opérateurs ne comprennent pas sera contourné. Impliquez-les dans la validation des alertes.
- Ne pas mesurer le ROI dès le départ — Définissez vos KPIs avant le déploiement : coût d’un arrêt non planifié, taux de rebuts actuel, coût de l’énergie.
Quel type de données pour intégrer le ML dans ma production ?
Le ML industriel fonctionne avec les données que vous avez déjà :
- Données capteurs : température, pression, vibration, débit, consommation électrique
- Données process : vitesse de ligne, paramètres de réglage, recettes de fabrication
- Données qualité : résultats de contrôle, taux de rebuts, codes de non-conformité
- Données de production : cadences, OEE, temps d’arrêt par cause
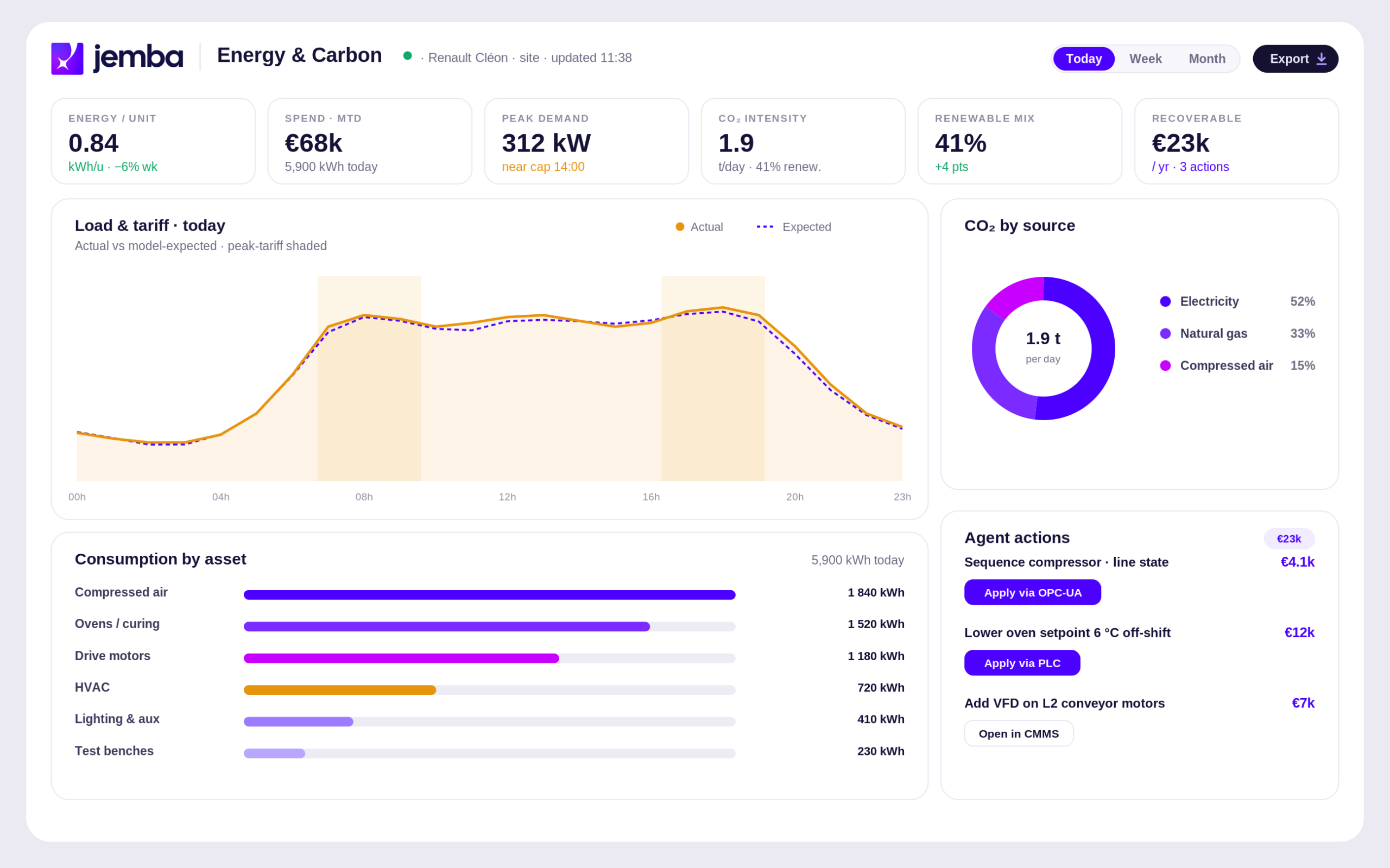
Jemba accepte toutes ces sources via CSV, API REST, ou connexion directe au flux TeepTrak. La plateforme gère automatiquement le nettoyage, l’alignement temporel et la normalisation des données. Pour voir concrètement comment, consultez la section plateforme Jemba.
Combien de temps pour intégrer le machine learning dans sa production ?
- Premiers insights : 4 semaines après la connexion des données
- Modèle en production sur une ligne : 6 à 8 semaines
- Déploiement multi-lignes : 18 semaines en moyenne
- ROI positif : dès l’année 1 (2,7 fois en moyenne)
Ces délais sont atteignables sans recruter, sans changer d’infrastructure, et sans immobiliser votre équipe IT. Les études de cas disponibles documentent ces résultats en détail.
See Jemba on your own data
A 30-minute session with a product specialist. No data scientist required, 48-hour setup.