
A Cognite Data Fusion Alternative for Production-Grade Industrial Machine Learning
JEMBA: A Cognite Data Fusion Alternative for Production-Grade Industrial Machine Learning
The search for a credible cognite data fusion alternative has emerged as a meaningful conversation in industrial software, particularly among mid-sized manufacturers seeking production-grade ML without the complexity and cost of a full industrial knowledge graph platform. Cognite has built a strong position in heavy industry — oil and gas, energy, power generation — by combining industrial data integration with a knowledge graph approach that enables sophisticated cross-system contextualization. The platform genuinely serves an important purpose for large industrial enterprises with complex multi-source data integration needs.
But as manufacturers push toward focused ML use cases — predictive maintenance, multi-variable quality analysis, yield optimization on hundreds of process variables — the broader platform footprint, large SI engagements and extended deployment cycles often slow time-to-value. JEMBA, developed by TEEPTRAK with 360+ industrial deployments across 30 countries, has emerged as the leading European cognite data fusion alternative for manufacturers seeking modern machine learning with predictable cost and rapid deployment.
This article examines why this trend is happening, how the two platforms compare, and which approach fits which situations.
What manufacturers expect from a cognite data fusion alternative
Conversations with industrial leaders evaluating alternatives reveal a consistent expectation set:
- Pre-built ML modules ready to deploy — quality root cause analysis, predictive maintenance, energy optimization, yield optimization, OEE — not knowledge graph platforms requiring custom ML application development
- Fast time-to-value — measurable insights within 4 weeks, full operational deployment within 12 weeks
- Predictable per-site economics — capped subscription costs rather than enterprise-scale licensing plus consulting
- Operational autonomy without data scientists or large SI teams — usable by existing production, quality and maintenance teams
- Multi-variable ML at scale — automated correlation analysis on hundreds of variables with measured detection rates
- Manufacturing-focused architecture — purpose-built for discrete and process manufacturing rather than horizontal heavy-industry data integration
JEMBA was designed from day one to meet exactly these expectations, with a vertical ML architecture purpose-built for industrial production environments.
Why Cognite Data Fusion faces architectural limits for focused production ML
To understand why a purpose-built cognite data fusion alternative like JEMBA delivers stronger ML outcomes for focused production use cases, it helps to examine the structural constraints of an industrial knowledge graph platform extended into ML.
Constraint 1: Knowledge graph foundation versus ML application focus
Cognite Data Fusion is built around an industrial knowledge graph that contextualizes data across multiple systems: PI historians, ERP, CMMS, engineering documents, 3D models, time-series sensors. This contextualization is genuinely powerful for cross-system queries and complex industrial data exploration. But it differs structurally from delivering production-grade ML use cases out of the box. JEMBA’s architecture treats ML applications as the central product, with data integration serving as supporting infrastructure rather than the primary value proposition.
Constraint 2: Heavy industry heritage versus manufacturing focus
Cognite’s strongest traction is in heavy industry: oil and gas, power generation, energy infrastructure. The platform serves these sectors well, with deep capabilities for asset performance management on capital-intensive equipment. JEMBA addresses both heavy industry and broader manufacturing — automotive, food, pharma, electronics, plastics, metal forming — with a single architecture optimized for the diversity of industrial production environments.
Constraint 3: Large enterprise deployment cycles
Cognite deployments typically target large industrial enterprises with substantial budgets, multi-year transformation roadmaps and major SI partner engagement. Mid-sized manufacturers, or focused ML projects within large groups, often find the resource requirements and timelines disproportionate to the actual ML scope. JEMBA delivers focused ML value in 8 to 12 weeks with predictable per-site subscription costs, suitable for both large enterprises and mid-sized organizations.
Constraint 4: Custom ML applications versus pre-built modules
Cognite Data Fusion provides the foundation for building ML applications, but the ML applications themselves must be developed by the customer or its SI partner. This adds cost, lengthens time-to-value and creates ongoing maintenance burden. By contrast, JEMBA ships with five pre-built ML modules that deploy in days rather than months.
None of these points diminish Cognite Data Fusion as an industrial knowledge graph platform — it remains a strong choice in that category for large heavy-industry enterprises. They simply explain why focused production-grade ML benefits from a different architectural foundation purpose-built for ML applications.
How JEMBA delivers focused production-grade ML
JEMBA was built ML-native from day one, with five characteristics that position it as a leading cognite data fusion alternative for focused production deployment:
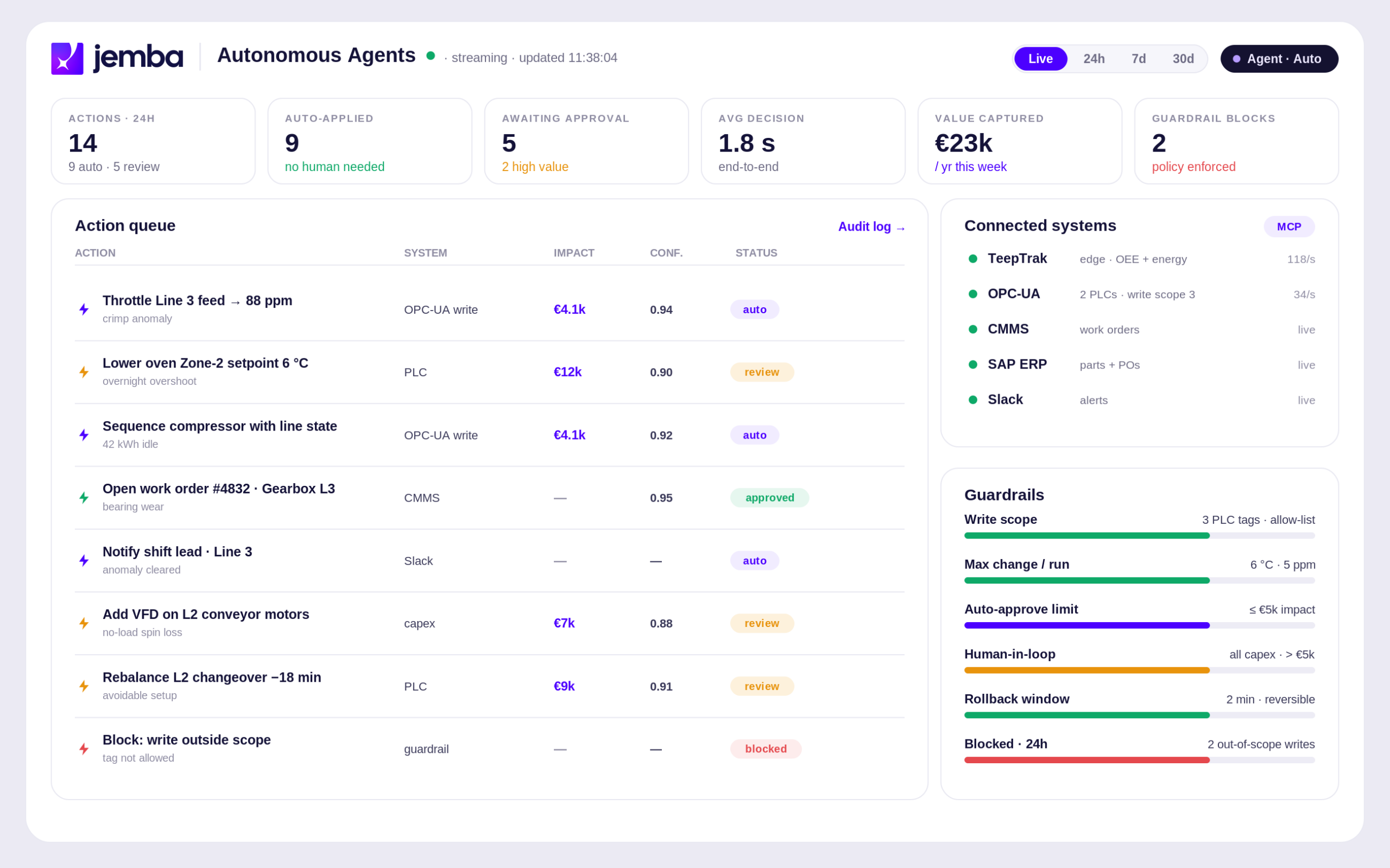
Pre-built ML modules for the top manufacturing use cases
Five modules come ready to deploy: quality root cause analysis, predictive maintenance, energy optimization, yield optimization, OEE improvement. Each is configured on customer data in days rather than months, with no custom ML development required.
4-week time-to-first-insight
JEMBA delivers measurable ML insights on customer data within 4 weeks, with full operational deployment in 8 to 12 weeks. This contrasts with knowledge graph platform deployments that typically require 12 to 24 months including data integration, contextualization modeling, custom ML development and validation.
Multi-variable analysis on hundreds of variables
JEMBA simultaneously analyzes hundreds — even thousands — of process variables to identify the 10 critical parameters that explain 80 percent of performance losses (the 10/80 rule). The flagship automotive case demonstrated this depth on 700 variables across 12 production lines.
Operational autonomy without data scientists
JEMBA is operated by existing production, quality and maintenance teams. Across 360+ deployments, customers have achieved 2.7x average year-1 ROI without hiring internal data scientists or engaging large SI teams.
European data sovereignty and predictable economics
JEMBA is a European-built platform with per-site subscription pricing capped and predictable. This differs from enterprise platforms with open-ended licensing scaled by data volume, users and use cases.
Explore the technical architecture in detail on the JEMBA platform page.
Head-to-head comparison: JEMBA versus Cognite Data Fusion
| Dimension | Cognite Data Fusion | JEMBA |
|---|---|---|
| Primary architecture | Industrial knowledge graph with ML | Vertical ML application platform |
| Heritage and focus | Heavy industry asset performance | Multi-sector manufacturing ML |
| Pre-built ML modules | Custom applications built on platform | 5 modules ready to deploy |
| Time-to-first-insight | 6 to 12 months typical | 4 weeks |
| Full ML deployment | 12 to 24 months typical | 8 to 12 weeks |
| Target customer size | Large enterprises | Mid to large enterprises |
| SI partner dependence | High | Minimal |
| ML detection rate | Not publicly benchmarked | 99.7 percent (360+ deployments) |
| Average year-1 ROI | Variable, often beyond year 2 | 2.7x average, pay-back under 6 months |
The 5 use cases where a cognite data fusion alternative delivers stronger results
Use case 1: Focused predictive maintenance without enterprise transformation
For manufacturers seeking targeted predictive maintenance value without committing to a full industrial knowledge graph deployment, JEMBA delivers focused ML in 8 to 12 weeks. Result across 360+ deployments: minus 35 percent unplanned downtime on average.
Use case 2: Quality root cause analysis for discrete manufacturing
For discrete manufacturing sectors (automotive, electronics, metal forming, plastics), where heavy-industry knowledge graph platforms have natural architectural limits, JEMBA delivers production-grade quality ML matched to discrete manufacturing data patterns. Average improvement: minus 22 percent scrap and rework.
Use case 3: Multi-variable yield optimization on complex processes
Flagship case: 700 process variables analyzed automatically, 10 critical parameters identified, yield improvement from 30 to 80 percent on the pilot line, more than 2 million euros saved in year 1. This level of automated multi-variable optimization is delivered without the deployment cycle of a full knowledge graph platform.
Use case 4: Energy optimization with rapid pay-back
JEMBA correlates energy consumption with operating conditions to identify wasteful regimes. Average improvement: minus 20 percent energy waste, with pay-back typically under 6 months at current European energy prices.
Use case 5: ML on mid-sized sites without enterprise budgets
Mid-sized manufacturers seeking targeted ML value find JEMBA’s deployment model — 8 to 12 weeks, predictable per-site subscription, operational autonomy — significantly better aligned with their resources and timelines than enterprise knowledge graph platforms.
The complementary path: combining Cognite and JEMBA
For large heavy-industry organizations with existing Cognite deployments, the most pragmatic approach is often complementarity rather than replacement. Cognite continues to handle the industrial knowledge graph and cross-system contextualization. JEMBA delivers focused production-grade ML use cases on top of the contextualized data, with measured detection rates and shop-floor integration.
Typical hybrid architecture
- Cognite layer — industrial knowledge graph, cross-system contextualization, complex multi-source data integration across asset and operational domains
- JEMBA layer — pre-built ML modules for predictive maintenance, quality root cause analysis, energy and yield optimization, with real-time operator alerts
- Integration — Cognite delivers contextualized data streams to JEMBA, JEMBA delivers ML insights and alerts back to operational workflows
This hybrid approach captures the cross-system data integration depth of Cognite alongside the production-grade ML depth of JEMBA — each platform playing to its architectural strengths.
The flagship reference: 2 million euros saved in year 1 on 12 production lines
The clearest demonstration of focused production-grade ML value comes from JEMBA’s flagship automotive deployment. A French Tier 1 automotive supplier operating 12 production lines had stagnant yield at 30 percent despite years of internal analytics efforts.
Results within 6 months of JEMBA deployment
- 700 process variables analyzed simultaneously across 12 lines
- 10 critical parameters identified, explaining 83 percent of yield losses
- 4 actionable levers validated by shop-floor teams
- Yield improvement from 30 percent to 80 percent on the pilot line
- Over 2 million euros saved in year 1
- Pay-back of 4 months on the JEMBA investment
- Zero data scientists hired by the customer
We saved more than two million euros in year one — with zero data scientists in-house. JEMBA revealed combinations of parameters our best process engineers had been looking for over three years.
— VP of Operations, Tier 1 Automotive Supplier, France
More cases in our industrial case studies.
When Cognite Data Fusion remains the right choice
To be balanced, Cognite Data Fusion remains a strong choice in specific scenarios:
- You operate large heavy-industry assets — oil and gas platforms, power generation, energy infrastructure where industrial knowledge graph depth is genuinely valuable
- You need cross-system contextualization across many data sources: historians, ERP, CMMS, engineering documents, 3D models, time-series
- You have a multi-year enterprise transformation roadmap with substantial budget and SI partner relationships
- Your scale justifies enterprise platform economics — typically multi-site global enterprises with hundreds of millions in capital assets
- You build custom industrial applications beyond pre-built ML use cases, requiring a flexible foundation
For focused ML use cases targeting production deployment where these conditions do not all hold, a vertical platform delivers significantly stronger outcomes faster.
How to evaluate JEMBA as your cognite data fusion alternative
Step A — Define focused ML use cases (week 1)
Identify the 1 to 3 ML use cases where a focused vertical platform fits better than an enterprise knowledge graph: predictive maintenance on a critical line, quality root cause analysis on a problematic SKU, yield optimization on a complex process.
Step B — Run a proof-of-value on real data (weeks 2 to 4)
JEMBA can demonstrate production-grade ML results on customer data within 4 weeks. This produces measured outcomes rather than theoretical capability comparisons.
Step C — Validate adoption with operational teams (weeks 4 to 8)
Test JEMBA alerts directly with production operators, quality supervisors and maintenance technicians. Adoption ease across operational teams is the most reliable long-term ROI predictor.
Step D — Build the financial and risk comparison (week 8)
Compare 3-year TCO including software, internal resources, SI partner fees and risk-adjusted timelines. For focused ML use cases, JEMBA’s predictable subscription typically wins decisively against enterprise platform deployments.
The 4 mistakes to avoid when evaluating a cognite data fusion alternative
- Comparing on platform breadth rather than ML outcomes — Cognite has broader industrial knowledge graph capabilities than JEMBA by design. Compare on the specific ML outcomes you actually need, not on platform features.
- Underestimating enterprise deployment cost and timeline — knowledge graph platforms typically require 12 to 24 months and substantial SI engagement. Factor these into TCO comparisons honestly.
- Limiting evaluation to heavy industry — Cognite’s heritage is heavy industry. JEMBA delivers equally strong results across discrete manufacturing, food, pharma, electronics. Match the platform to your full site portfolio.
- Forgetting operational adoption testing — even sophisticated ML models are worthless if shop-floor teams cannot act on them. Test adoption explicitly with target users during evaluation.
Conclusion: a credible cognite data fusion alternative for production-grade industrial ML
For manufacturers seeking a credible cognite data fusion alternative for focused production-grade industrial machine learning faster and at lower TCO, JEMBA represents the leading European choice in 2026. With 360+ deployments across 30 countries, 99.7 percent ML detection rate, 4-week time-to-first-insight, pre-built modules and 2.7x average year-1 ROI, the platform delivers what enterprise knowledge graph platforms structurally cannot achieve in the same timeframe.
This positioning does not displace Cognite Data Fusion — which remains a strong choice for large heavy-industry enterprises with cross-system contextualization needs. But for manufacturers whose ML ambitions are focused, urgent and span multiple sectors, a vertical platform like JEMBA delivers dramatic differences in time, cost and ROI. The most sophisticated organizations often combine both, capturing knowledge graph integration depth alongside production-grade ML breadth.
To evaluate JEMBA on your own use cases, the best starting point remains a personalized demo on real production data.
See Jemba on your own data
A 30-minute session with a product specialist. No data scientist required, 48-hour setup.