
La Règle des 10/80 en Industrie : Comment le Machine Learning Identifie les 10 Variables qui Causent 80% des Pertes
Optimisation Procédé Multi-Variables ML : la Règle des 10/80 pour Identifier les Vrais Leviers de Performance Industrielle
L’optimisation procédé multi-variables ML repose sur un principe que les économistes appellent Pareto, et que les industriels modernes redécouvrent grâce au machine learning : dans la plupart des process de production, une poignée de variables explique la majorité des pertes. C’est la règle des 10/80 : 10 variables sur plusieurs centaines causent typiquement 80 pour cent des écarts de performance.
Cette règle, vérifiée empiriquement sur plus de 360 déploiements industriels JEMBA, change radicalement la manière dont les directeurs de production doivent aborder l’optimisation. Plutôt que de tenter d’améliorer simultanément des centaines de paramètres avec des analyses statistiques classiques, l’optimisation procédé multi-variables ML permet d’identifier précisément les leviers critiques — et de concentrer l’effort là où il rapporte vraiment.
Qu’est-ce que la règle des 10/80 en optimisation procédé multi-variables ML
La règle des 10/80 est une variante industrielle de la loi de Pareto (80/20) adaptée aux contextes de production complexes. Elle énonce que :
Dans un procédé industriel complexe, environ 10 variables process expliquent 80 pour cent de la variance des pertes de performance.
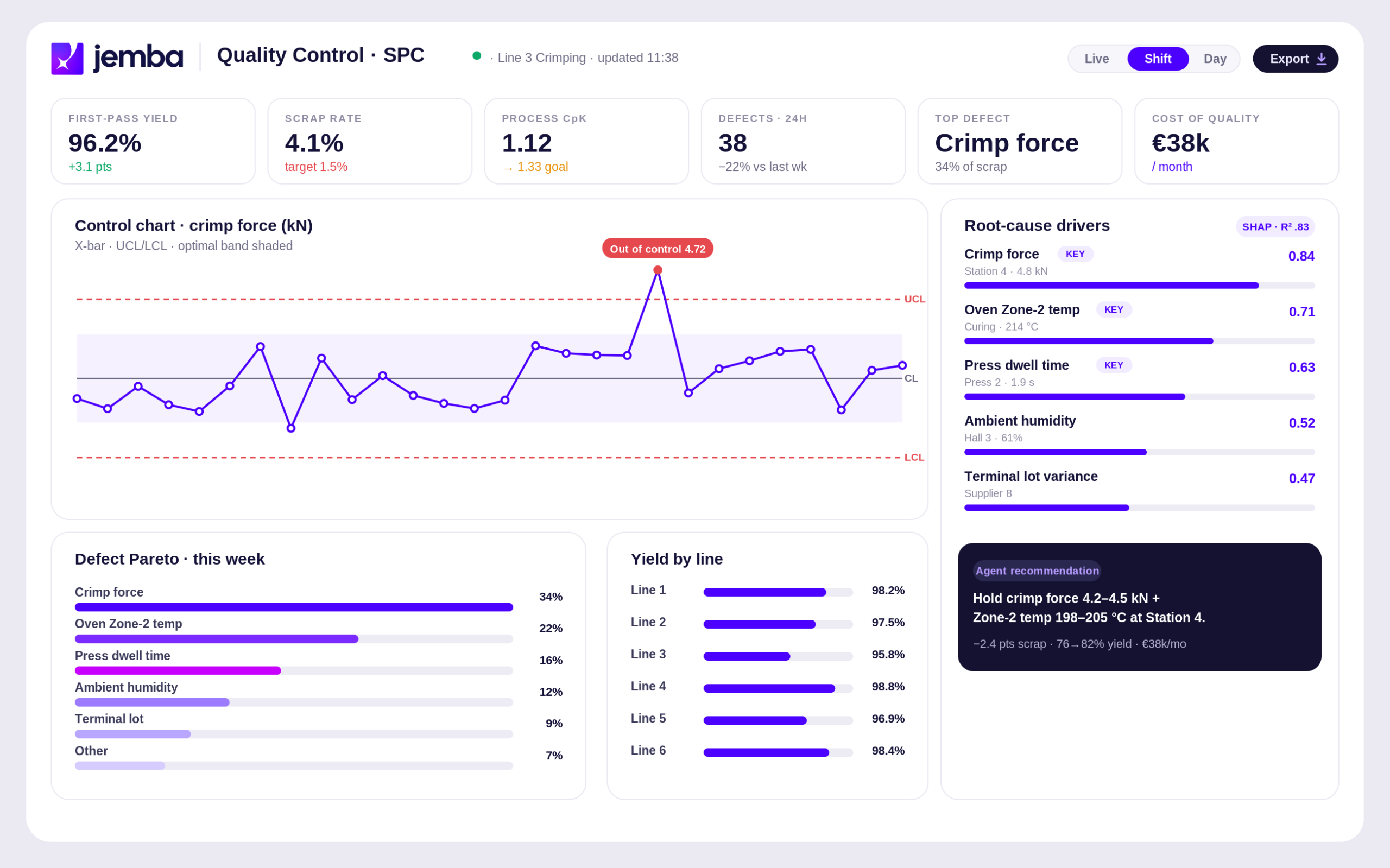
Cette règle n’est pas un postulat théorique : elle est observée empiriquement sur l’écrasante majorité des déploiements ML industriels. Sur le cas phare JEMBA d’un équipementier automobile rang 1 français, l’analyse de plus de 700 variables a révélé que seuls 10 paramètres expliquaient 83 pour cent des pertes de rendement, et que 4 leviers principaux étaient directement actionnables par les équipes terrain.
Pourquoi la règle des 10/80 est sous-exploitée sans optimisation procédé multi-variables ML
Avant l’arrivée des plateformes ML industrielles modernes, identifier les 10 variables critiques parmi des centaines relevait du défi insurmontable. Trois obstacles structurels expliquent cette difficulté :
1. La limite de l’analyse statistique classique
Les méthodes statistiques traditionnelles — régressions multivariées, analyses en composantes principales, tests d’hypothèse — peinent face à plusieurs caractéristiques des données industrielles : non-linéarités, interactions complexes entre variables, séries temporelles irrégulières, présence de variables qualitatives. L’analyste qui dispose de 700 variables mais d’outils statistiques classiques n’a que 80 ou 90 pour cent de chances d’identifier les bonnes variables critiques.
2. La limite de la connaissance terrain
Les ingénieurs procédés et les chefs d’équipe disposent d’une expertise terrain précieuse, mais limitée par leur capacité cognitive à intégrer simultanément des centaines de variables. Personne ne peut, mentalement, croiser 700 séries temporelles sur 6 mois pour identifier des combinaisons précises.
3. La limite des outils data science généralistes
Les plateformes data science généralistes (Dataiku, DataRobot, SageMaker) peuvent théoriquement faire ce travail, mais demandent une équipe data interne, un cycle projet long, et une expertise pointue. Pour la majorité des sites industriels, cette approche est inaccessible.
L’optimisation procédé multi-variables ML verticale, telle que proposée par JEMBA, résout simultanément les trois obstacles : algorithmes adaptés aux non-linéarités industrielles, capacité d’analyse simultanée de centaines de variables, et accessibilité no-code aux équipes terrain.
Comment fonctionne la règle des 10/80 en pratique
Étape 1 — Collecter toutes les variables potentiellement pertinentes
Contrairement à l’approche statistique classique qui présélectionne les variables à analyser, l’optimisation procédé multi-variables ML commence par collecter tout ce qui est mesurable : températures, pressions, vibrations, cadences, paramètres machines, conditions environnementales, données qualité, paramètres opérateur, données de maintenance. Plus la collecte est exhaustive, plus l’analyse sera robuste.
Étape 2 — Définir la variable cible
L’objectif d’optimisation doit être clairement défini : taux de rebut, rendement matière, consommation énergétique, OEE, taux de conformité qualité. Le ML cherchera ensuite les variables qui expliquent statistiquement les variations de cette cible.
Étape 3 — Entraîner le modèle ML sur l’historique
Le modèle s’entraîne sur les données historiques (3 à 6 mois minimum pour des résultats robustes). Il teste les corrélations linéaires, non-linéaires, les interactions entre variables, et identifie les configurations les plus prédictives de la variable cible.
Étape 4 — Extraire les variables critiques et leur poids relatif
Le modèle restitue un classement des variables par ordre d’importance. Typiquement, les 10 premières variables cumulent 80 pour cent de l’explication de la variance. Les suivantes deviennent rapidement marginales.
Étape 5 — Traduire en leviers d’action
Sur les 10 variables critiques, certaines sont directement actionnables (paramètres réglables), d’autres sont contextuelles (météo, qualité matière première). Le travail final consiste à identifier les 3 à 5 leviers principaux et à définir un plan d’action. Pour voir cette méthodologie en action, explorez la plateforme JEMBA.
Le cas concret : 700 variables, 10 leviers, plus de 2 millions d’euros économisés
L’illustration la plus complète de l’optimisation procédé multi-variables ML reste le cas phare JEMBA d’un équipementier automobile rang 1 français. Sur 12 lignes de production, chaque ligne générait plus de 700 variables. La question : parmi ces 700 variables, lesquelles expliquent réellement les pertes de rendement ?
Avant JEMBA
- Rendement moyen sur la ligne pilote : 30 pour cent
- Pertes annuelles estimées : plusieurs millions d’euros
- Plusieurs années d’analyses statistiques internes sans résultat actionnable
- Tentatives d’amélioration sur 50+ paramètres, sans gain mesurable
Après JEMBA — résultats en 6 mois
- 10 paramètres critiques identifiés sur 700 variables analysées
- 83 pour cent des pertes expliquées par ces 10 paramètres
- 4 leviers principaux directement actionnables par les équipes terrain
- Rendement passé de 30 à 80 pour cent sur la ligne pilote
- Plus de 2 millions d’euros économisés la première année sur 12 lignes
- ROI année 1 supérieur à 8 fois sur la ligne pilote
La règle des 10/80 n’est pas une théorie : c’est exactement ce que nous avons observé. Sur 700 variables, 4 leviers ont changé notre rendement de 30 à 80 pour cent. Nous avons économisé plus de deux millions d’euros la première année.
— VP of Operations, équipementier automobile rang 1, France
Le détail méthodologique est disponible dans nos études de cas industrielles.
Les 6 cas d’usage où la règle des 10/80 transforme la performance industrielle
1. Optimisation du rendement matière
Particulièrement puissant dans l’agroalimentaire et la chimie où la matière première représente 50 à 70 pour cent du coût de revient. Identifier les variables qui maximisent le rendement matière vaut typiquement plusieurs centaines de milliers d’euros par an sur un site moyen.
2. Réduction des rebuts et retouches
Identifier les combinaisons de paramètres qui causent les défauts qualité, plutôt que de tâtonner sur des contrôles renforcés. Gain moyen : moins 22 pour cent de rebuts.
3. Optimisation énergétique
Identifier les régimes de fonctionnement énergivores et les conditions qui les déclenchent. Particulièrement critique en 2026 face à l’inflation énergétique. Gain moyen : moins 20 pour cent de gaspillage.
4. Optimisation de l’OEE
Comprendre les causes racines des pertes de performance — micro-arrêts, ralentissements, défauts — au lieu de simplement les mesurer. Gain typique : +5 à +15 points d’OEE.
5. Optimisation maintenance prédictive
Identifier les variables annonciatrices de pannes équipement, parfois plusieurs jours avant la défaillance. Réduction moyenne du temps d’arrêt non planifié : moins 35 pour cent.
6. Optimisation de la stabilité procédé
Identifier les variables qui causent les dérives lentes du procédé, permettant des ajustements préventifs plutôt que correctifs.
Les 5 conditions pour réussir un projet d’optimisation procédé multi-variables ML
- Une collecte de données exhaustive — ne présélectionnez pas les variables avant l’analyse. Laissez le ML découvrir les corrélations inattendues. Le piège classique consiste à exclure dès le départ les variables jugées « non pertinentes » par les experts métier.
- Une variable cible bien définie — taux de rebut, rendement, OEE, consommation énergétique. Précise, mesurable, alignée avec les enjeux business.
- Un historique de 3 à 6 mois minimum — moins, et le modèle manque de robustesse. Plus, et les améliorations parasites entrent dans l’analyse.
- Une plateforme ML adaptée aux séries temporelles industrielles — privilégiez une solution verticale comme JEMBA plutôt qu’un outil généraliste qui devra être paramétré sur mesure.
- Une boucle de validation avec les équipes terrain — les variables identifiées par le ML doivent être confrontées à la connaissance métier. Cette validation croisée éclaire les fausses corrélations et révèle des causalités cachées.
Les 4 pièges qui font échouer un projet d’optimisation procédé multi-variables ML
- Préselectionner les variables avant l’analyse — laisser le ML découvrir les corrélations inattendues est essentiel. Les meilleures découvertes viennent souvent de variables qu’aucun expert n’aurait priorisées.
- Confondre corrélation et causalité — le ML identifie des corrélations statistiques. La causalité doit être validée par l’expertise métier et, idéalement, par des expérimentations contrôlées.
- Négliger l’actionabilité des variables — une variable très prédictive mais non-actionnable (par exemple, la température extérieure) reste utile pour la prédiction, mais ne génère pas de levier d’action direct.
- Vouloir tout optimiser en parallèle — concentrez-vous d’abord sur les 3 à 5 leviers principaux. La sur-optimisation simultanée crée des effets de bord difficiles à interpréter.
Comment démarrer un projet d’optimisation procédé multi-variables ML
La méthode JEMBA en 4 étapes :
Étape A — Audit data (semaines 1-2)
Cartographier toutes les variables disponibles sur la ligne pilote. Vérifier la qualité des données (timestamps, complétude, fiabilité capteurs).
Étape B — Connexion à la plateforme (semaines 2-3)
Brancher les sources de données (historian, SCADA, MES, CSV) à JEMBA. Définir la variable cible.
Étape C — Entraînement et identification des variables critiques (semaines 3-5)
Le modèle s’entraîne automatiquement sur l’historique. Il restitue le classement des variables et identifie les leviers principaux.
Étape D — Validation, déploiement et mesure du ROI (semaines 5-12)
Validation des hypothèses avec les équipes terrain. Mise en place des recommandations. Mesure des gains.
Délai total typique : 8 à 12 semaines pour un premier cycle d’optimisation procédé multi-variables ML complet. Sans recruter, sans data scientist.
Conclusion : la règle des 10/80, un avantage compétitif accessible à toute usine
L’optimisation procédé multi-variables ML guidée par la règle des 10/80 est l’une des transformations industrielles les plus puissantes des cinq dernières années. Elle change radicalement la productivité de la démarche d’amélioration continue : plutôt que de tâtonner sur des dizaines de paramètres, vos équipes se concentrent sur les 3 à 5 leviers qui pèsent vraiment.
Cette approche, longtemps réservée aux grands groupes disposant d’équipes data science internes, est désormais accessible à toute usine grâce aux plateformes ML verticales comme JEMBA. À la clé : un ROI moyen de 2,7 fois en année 1, et des cas phares au-delà de 8 fois sur les lignes prioritaires.
See Jemba on your own data
A 30-minute session with a product specialist. No data scientist required, 48-hour setup.