
Analyse des Causes Racines en Temps Réel : Pourquoi 700 Variables Changent Tout en Production Industrielle
Analyse Causes Racines Temps Réel : Pourquoi 700 Variables Changent Tout en Production Industrielle
L’analyse causes racines temps réel est en train de redéfinir la manière dont les usines pilotent leur performance. Pendant des décennies, l’analyse des causes racines (Root Cause Analysis, RCA) reposait sur des méthodes a posteriori : un défaut survient, une équipe analyse les données la semaine suivante, propose des hypothèses, lance des plans d’action, et mesure les résultats plusieurs mois plus tard. Ce cycle, hérité de la qualité totale des années 1980, atteint aujourd’hui ses limites face à la complexité des procédés modernes.
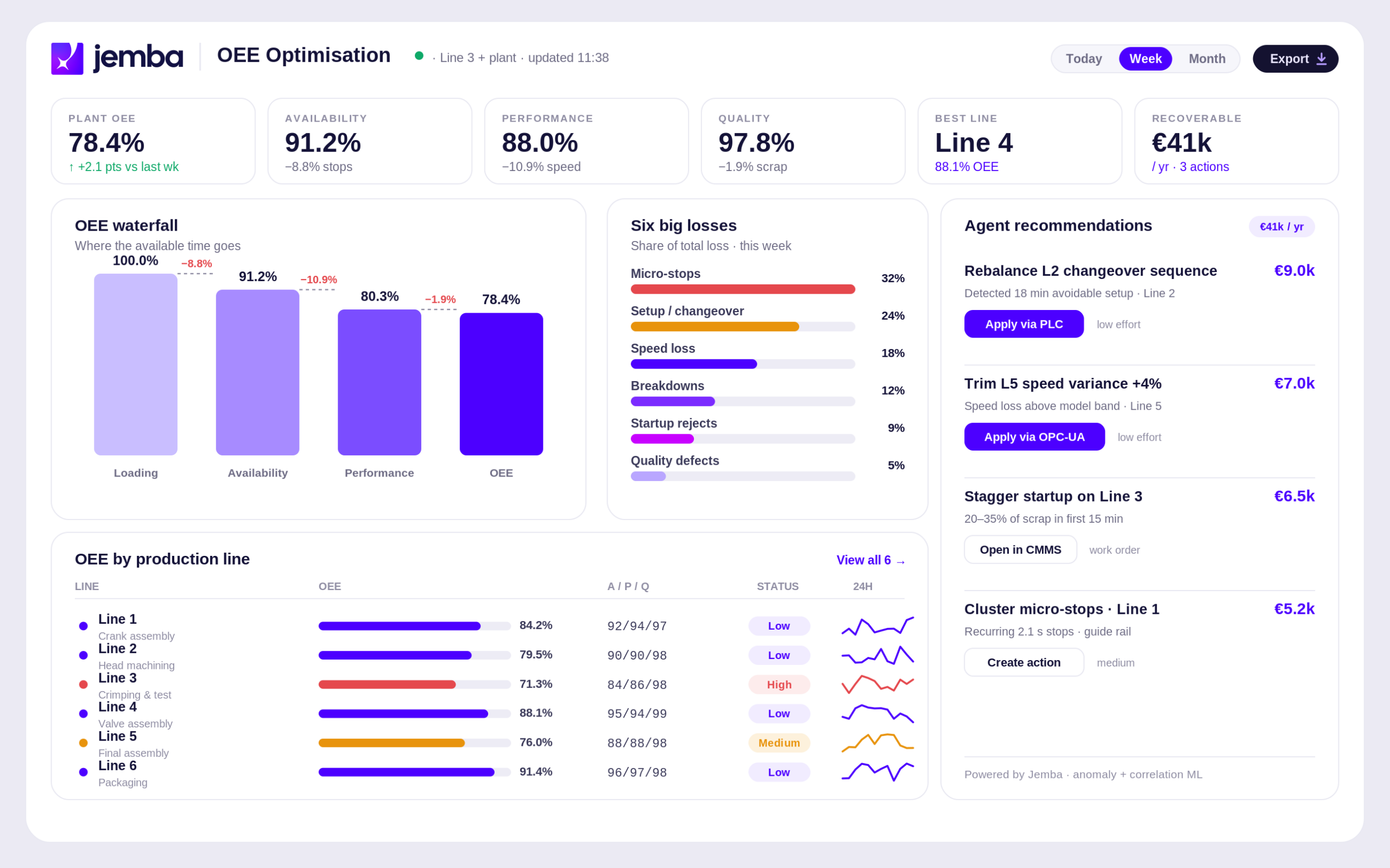
La nouvelle génération de plateformes ML industrielles change radicalement ce paradigme. Grâce à l’analyse simultanée de centaines de variables process en temps réel, l’identification des causes racines passe de plusieurs semaines à quelques secondes. Sur le cas phare JEMBA d’un équipementier automobile rang 1 français, plus de 700 variables ont été analysées en continu pour révéler les 4 leviers qui expliquaient 83 pour cent des pertes de rendement — un résultat impossible à atteindre avec les méthodes RCA traditionnelles.
Cet article explique pourquoi l’analyse causes racines temps réel représente la rupture la plus importante en pilotage industriel depuis l’introduction du Lean Manufacturing, et comment la déployer dans votre usine sans recruter une équipe de data scientists.
Pourquoi l’analyse causes racines traditionnelle ne suffit plus en 2026
Les méthodes RCA classiques — 5 pourquoi, diagramme d’Ishikawa, AMDEC, arbre des causes, méthode des 8D — restent des outils précieux pour les équipes qualité et maintenance. Mais elles partagent quatre limites structurelles qui les rendent insuffisantes face à la complexité des usines modernes.
1. La temporalité décalée
Les RCA classiques sont réactives : elles s’enclenchent après l’incident. Le délai entre la survenue du problème, l’analyse, l’identification des causes et la mise en place des actions correctives se chiffre typiquement en semaines, voire en mois. Pendant ce temps, les pertes continuent.
2. La limite cognitive humaine
Une équipe RCA traditionnelle peut intégrer mentalement une dizaine de variables clés. Au-delà, l’analyse devient subjective et biaisée par les hypothèses initiales. Or les procédés industriels modernes génèrent typiquement des centaines, voire des milliers de variables exploitables. La majorité reste inexploitée.
3. Le biais de confirmation
Les équipes RCA arrivent rarement vierges sur un problème. Chaque analyste a ses intuitions, son expérience, ses hypothèses préférées. Cela accélère l’analyse, mais conduit aussi à confirmer ce qu’on cherche au lieu de découvrir ce qui se cache. Le ML, lui, n’a pas de biais : il examine équitablement toutes les corrélations.
4. L’invisibilité des interactions complexes
Une cause racine n’est souvent pas une variable unique, mais une combinaison de variables interagissant dans certaines conditions. Une RCA manuelle peut difficilement identifier ces combinaisons sur des centaines de paramètres. Le ML, oui — c’est même précisément son point fort.
Comment l’analyse causes racines temps réel transforme la production
L’analyse causes racines temps réel par machine learning combine trois capacités que les méthodes traditionnelles ne peuvent égaler simultanément :
- L’instantanéité — les causes sont identifiées au moment où le problème apparaît, voire avant qu’il ne devienne visible
- L’exhaustivité — toutes les variables process sont analysées simultanément, sans préselection humaine biaisante
- L’objectivité statistique — les corrélations sont mesurées rigoureusement, pas supposées
Le résultat opérationnel est considérable : moins 35 pour cent de temps d’arrêt non planifié, moins 22 pour cent de rebuts, et un pay-back moyen inférieur à 6 mois sur les déploiements JEMBA.
Pourquoi 700 variables changent tout dans l’analyse causes racines
Le chiffre de 700 variables n’est pas anodin. C’est le seuil à partir duquel l’analyse humaine devient quasi-impossible, et où le ML révèle des découvertes inaccessibles autrement. Voici pourquoi cette échelle change tout.
1. Les causes racines se cachent souvent dans les variables sous-suivies
Les équipes industrielles surveillent généralement 20 à 50 variables clés au quotidien — celles considérées comme critiques. Mais les causes racines des problèmes inexpliqués se cachent souvent dans les centaines de variables “secondaires” qui ne sont jamais regardées. Le ML examine tout, sans distinction d’importance présumée. C’est ainsi qu’il révèle des corrélations inattendues.
2. Les interactions multi-variables sont la norme, pas l’exception
Sur 700 variables, le nombre de combinaisons 2 à 2 dépasse 240 000. Les combinaisons triples se comptent en dizaines de millions. Aucune équipe humaine ne peut explorer cet espace. Un algorithme ML, oui — en quelques minutes.
3. La détection précoce permet l’action avant le problème
Avec 700 variables suivies en temps réel, les signaux faibles précurseurs de défaillance deviennent détectables des heures, voire des jours avant la manifestation du problème. C’est l’essence même de la maintenance prédictive : intervenir avant la panne, pas après. Pour comprendre cette logique, explorez la plateforme JEMBA.
4. La capitalisation du savoir-faire devient massive
Chaque combinaison de variables identifiée comme cause racine devient une connaissance capitalisée par la plateforme. Avec le temps, votre usine devient progressivement “plus intelligente” — capable de reconnaître automatiquement les configurations à risque qu’elle a déjà rencontrées.
Le cas concret : 700 variables, 4 leviers, plus de 2 millions d’euros économisés
Le meilleur exemple opérationnel de l’analyse causes racines temps réel reste le déploiement JEMBA chez un équipementier automobile rang 1 français. Sur 12 lignes de production, chaque ligne générait plus de 700 variables process : températures, pressions, vibrations, cadences, paramètres machines, conditions environnementales, données qualité, paramètres opérateur.
Le contexte avant JEMBA
Le rendement moyen sur la ligne pilote stagnait à 30 pour cent depuis plusieurs années. Les équipes qualité et procédé avaient mené de nombreuses RCA traditionnelles. Les analyses avaient identifié plusieurs causes plausibles, mais aucune n’avait permis d’enclencher une amélioration significative. La raison : les vraies causes racines étaient des combinaisons de 4 paramètres interagissant dans des configurations rares mais critiques — invisibles à l’analyse manuelle.
La méthode JEMBA en 6 mois
- Connexion automatique aux 700 variables process des 12 lignes
- Analyse ML continue en temps réel sur 6 mois d’historique puis sur les flux live
- Identification de 10 paramètres clés expliquant 83 pour cent de la variance des pertes
- Restitution en langage métier compréhensible par les équipes terrain
- Mise en place d’alertes temps réel sur les combinaisons critiques
Les résultats
- Rendement passé de 30 à 80 pour cent sur la ligne pilote
- Plus de 2 millions d’euros économisés la première année sur 12 lignes
- Pay-back de 4 mois sur l’investissement JEMBA
- ROI année 1 supérieur à 8 fois sur la ligne pilote
L’analyse causes racines en temps réel a révélé des combinaisons de 4 paramètres que nos meilleurs ingénieurs procédés cherchaient depuis 3 ans. Nous avons économisé plus de deux millions d’euros la première année.
— VP of Operations, équipementier automobile rang 1, France
Découvrez le détail méthodologique dans nos études de cas industrielles.
Les 6 cas d’usage où l’analyse causes racines temps réel transforme la performance
1. Diagnostic immédiat des dérives qualité
Quand un défaut apparaît sur une ligne, l’analyse causes racines temps réel identifie en quelques secondes les paramètres responsables — au lieu d’une enquête qualité de plusieurs semaines. Gain typique : moins 22 pour cent de rebuts.
2. Identification des causes d’arrêts récurrents
Pour les équipements qui tombent en panne périodiquement sans cause identifiée, l’analyse ML révèle les combinaisons de variables précédant systématiquement les pannes. Réduction moyenne du temps d’arrêt non planifié : moins 35 pour cent.
3. Compréhension des micro-arrêts inexpliqués
Les micro-arrêts (moins de 5 minutes) sont la première cause de perte d’OEE et la plus difficile à diagnostiquer manuellement. L’analyse causes racines temps réel les attribue automatiquement à des causes statistiquement validées.
4. Investigation des dérives énergétiques
Quand la facture énergétique augmente sans raison apparente, l’analyse ML identifie les régimes de fonctionnement énergivores et les conditions qui les déclenchent. Gain moyen : moins 20 pour cent de gaspillage énergétique.
5. Décodage des écarts de rendement matière
Dans l’agroalimentaire, la chimie ou la plasturgie, le rendement matière varie sans cause évidente. L’analyse causes racines temps réel révèle les paramètres procédé et matière qui causent les pertes — gain typique de 2 à 5 pour cent de rendement matière supplémentaire.
6. Validation rapide des hypothèses d’amélioration
Quand une équipe teste une modification de paramètre, l’analyse temps réel mesure immédiatement son impact sur les variables aval. Plus besoin d’attendre 3 mois pour valider une hypothèse — quelques jours suffisent.
Comment déployer l’analyse causes racines temps réel sans data scientist
Contrairement à ce qu’on pourrait imaginer, déployer une analyse causes racines temps réel par ML ne nécessite plus d’équipe data interne. Voici la méthode JEMBA en 4 étapes :
Étape A — Connexion exhaustive des sources de données (semaines 1-2)
Connectez l’ensemble des sources disponibles : historian, SCADA, MES, capteurs IoT TeepTrak, données qualité, fichiers CSV. Pas de présélection — laissez la plateforme analyser tout.
Étape B — Définition des problèmes prioritaires (semaines 2-3)
Identifiez les 1 à 3 problèmes les plus coûteux ou récurrents que vous voulez résoudre : taux de défaut élevé, arrêts non planifiés sur un équipement clé, dérive énergétique sur un atelier. Pas plus de 3 problèmes en première vague.
Étape C — Entraînement automatique et identification des causes racines (semaines 3-5)
Le modèle ML JEMBA s’entraîne automatiquement sur 3 à 6 mois d’historique. Il classe les variables par ordre d’importance statistique et identifie les combinaisons explicatives. Taux de détection moyen : 99,7 pour cent. Temps de réponse : moins de 2 secondes.
Étape D — Mise en production des alertes temps réel (semaines 5-12)
Les combinaisons critiques identifiées génèrent des alertes temps réel sur le tableau de bord des opérateurs, avec des recommandations en langage métier. Phase d’ajustement des seuils, d’intégration aux workflows opérationnels et de formation légère des équipes.
Délai total typique : 8 à 12 semaines pour un premier cas d’usage en production. Sans data scientist côté client, sans changement d’infrastructure majeur.
Les 5 conditions pour réussir un projet d’analyse causes racines temps réel
- Une collecte exhaustive des variables disponibles — ne préselectionnez pas. Les meilleures découvertes viennent souvent de variables qu’aucun expert n’aurait priorisées.
- Un historique de 3 à 6 mois minimum — pour que le ML capture suffisamment de cas représentatifs des conditions normales et anormales.
- Une définition précise des problèmes à diagnostiquer — taux de défaut, durée d’arrêt, consommation énergétique. Mesurable, précis, aligné avec les enjeux business.
- Une boucle de validation avec les experts métier — les corrélations identifiées par le ML doivent être confrontées à la connaissance terrain pour distinguer causalité et coïncidence.
- Une intégration aux workflows opérationnels — les alertes doivent apparaître là où les opérateurs travaillent déjà, pas dans un énième dashboard isolé.
Les 4 erreurs à éviter dans un projet d’analyse causes racines temps réel
- Confondre corrélation et causalité — le ML révèle des corrélations statistiques. La causalité doit être validée par l’expertise métier et, idéalement, par des essais contrôlés.
- Vouloir tout diagnostiquer en parallèle — concentrez-vous sur 1 à 3 problèmes prioritaires en première vague. La sur-globalisation dilue les résultats.
- Ignorer les experts métier — l’analyse ML ne remplace pas l’expertise terrain, elle la complète. Les meilleurs déploiements combinent les deux.
- Sous-estimer la qualité des données — un modèle d’analyse causes racines temps réel ne sera fiable que si vos données le sont. Auditez les timestamps, la complétude et la précision des capteurs avant le déploiement.
L’impact stratégique de l’analyse causes racines temps réel
Au-delà des gains opérationnels immédiats, l’analyse causes racines temps réel transforme structurellement la culture qualité d’une usine. Cinq évolutions notables observées sur les déploiements JEMBA :
- Accélération du cycle d’amélioration continue — de plusieurs mois à quelques jours par cycle
- Démocratisation de l’analyse — les chefs d’équipe deviennent autonomes sur les diagnostics, sans dépendre d’une équipe centrale
- Réduction des biais d’analyse — les hypothèses sont validées statistiquement, pas confirmées par habitude
- Capitalisation continue du savoir-faire — chaque diagnostic enrichit la connaissance de la plateforme
- Anticipation au lieu de réaction — la culture qualité passe du curatif au prédictif
Conclusion : l’analyse causes racines temps réel, un standard de performance 2026
L’analyse causes racines temps réel n’est plus une technologie d’avant-garde réservée aux grands groupes : c’est devenue une nécessité opérationnelle pour toute usine qui veut maintenir sa compétitivité en 2026. Les chiffres consolidés sur 360+ déploiements JEMBA (moins 35 pour cent d’arrêts, moins 22 pour cent de rebuts, ROI 2,7 fois en année 1) en font l’un des leviers d’amélioration continue les plus rentables disponibles aujourd’hui.
L’analyse de 700 variables ne change pas seulement la performance opérationnelle — elle change la culture qualité de l’usine, en passant du diagnostic réactif à la prédiction continue. Pour évaluer le potentiel sur vos propres lignes, le meilleur point de départ reste une démo sur vos données réelles.
See Jemba on your own data
A 30-minute session with a product specialist. No data scientist required, 48-hour setup.