
Détection d’Anomalies en Temps Réel dans l’Industrie : Comment le Machine Learning Anticipe les Pannes
Détection Anomalies Temps Réel Industrie : Comment le Machine Learning Anticipe les Pannes
La détection anomalies temps réel industrie est devenue l’un des cas d’usage les plus rentables du machine learning industriel. La promesse est simple, mais elle change profondément la performance opérationnelle : détecter les déviations anormales du comportement de vos équipements ou de vos process avant qu’elles ne se transforment en arrêts non planifiés, en défauts qualité ou en surconsommation énergétique.
Sur les 360+ déploiements JEMBA, les industriels qui ont mis en place une détection d’anomalies par ML observent en moyenne moins 35 pour cent de temps d’arrêt non planifié, avec un taux de détection ML de 99,7 pour cent et un temps de réponse inférieur à 2 secondes. Cet article explique comment fonctionne la détection d’anomalies en temps réel par machine learning, quelles performances en attendre, et comment la déployer dans votre usine sans recruter de data scientist.
Qu’est-ce que la détection anomalies temps réel industrie par machine learning
La détection anomalies temps réel industrie repose sur un principe fondamental : un modèle ML apprend le comportement normal de vos équipements et de vos process à partir de l’historique, puis surveille en continu les nouvelles données pour détecter toute déviation statistiquement anormale par rapport à ce comportement de référence.
Trois différences essentielles avec les méthodes de surveillance traditionnelles (seuils fixes, alarmes SCADA, contrôles SPC) :
- Apprentissage automatique de la normalité — le ML ne se contente pas de surveiller un seuil fixe pour chaque variable. Il apprend les motifs normaux complexes : oscillations cycliques, dérives saisonnières, corrélations entre variables, transitions de régime.
- Détection multi-variables — une anomalie peut résulter d’une combinaison de variables qui, isolément, restent dans leurs limites normales. Seul le ML capture ces signatures complexes.
- Apprentissage continu — le modèle peut s’adapter aux évolutions normales du process (vieillissement contrôlé, changement de référence, ajustements de réglage), tout en restant sensible aux anomalies réelles.
Pourquoi la détection anomalies temps réel industrie dépasse les méthodes classiques
Les méthodes traditionnelles de surveillance industrielle — alarmes sur seuils fixes, cartes de contrôle SPC, surveillance vibratoire classique — restent utiles mais souffrent de quatre limites structurelles.
1. Le compromis sensibilité / faux positifs
Avec des seuils fixes, baisser le seuil augmente la sensibilité aux anomalies réelles, mais multiplie aussi les faux positifs. À l’inverse, remonter le seuil réduit les faux positifs mais fait passer à côté des signaux faibles précurseurs. Le ML résout ce dilemme en apprenant des motifs complexes plutôt que des seuils simples.
2. L’incapacité à voir les corrélations
Une alarme classique surveille une variable à la fois. Mais une anomalie réelle se manifeste souvent par une combinaison subtile : la température est normale, la pression est normale, le débit est normal, mais leur combinaison à cet instant précis n’a aucun précédent dans l’historique. C’est là que le ML excelle.
3. La rigidité face aux régimes variables
Une usine moderne ne fonctionne pas dans un régime unique : démarrages, arrêts, changements de format, montées en cadence, ralentissements. Les seuils fixes génèrent inévitablement des alarmes parasites lors de ces transitions. Le ML apprend à reconnaître les différents régimes de fonctionnement et adapte sa surveillance.
4. L’absence d’apprentissage
Une alarme classique reste figée. Un modèle ML évolue : il apprend de chaque incident, de chaque retour opérateur, et améliore continuellement la qualité de ses détections.
Pour évaluer ces différences sur vos propres données, explorez la plateforme JEMBA.
Les performances mesurées de la détection anomalies temps réel industrie
Sur les 360+ déploiements JEMBA, les indicateurs consolidés sont publics et reproductibles :
- 99,7 pour cent de taux de détection ML
- Moins de 2 secondes de temps de réponse moteur ML
- Moins 35 pour cent de temps d’arrêt non planifié
- Détection précoce typique de plusieurs heures à plusieurs jours avant la panne
- Taux de faux positifs maîtrisé grâce à l’apprentissage multi-variables
- 2,7 fois de ROI moyen en année 1
Ces indicateurs sont consolidés sur l’ensemble de la base installée, pas extraits de cas isolés. Ils permettent une projection robuste pour un nouvel acheteur.
Les 5 types d’anomalies détectées en temps réel par le machine learning
1. Anomalies de vibration sur équipements rotatifs
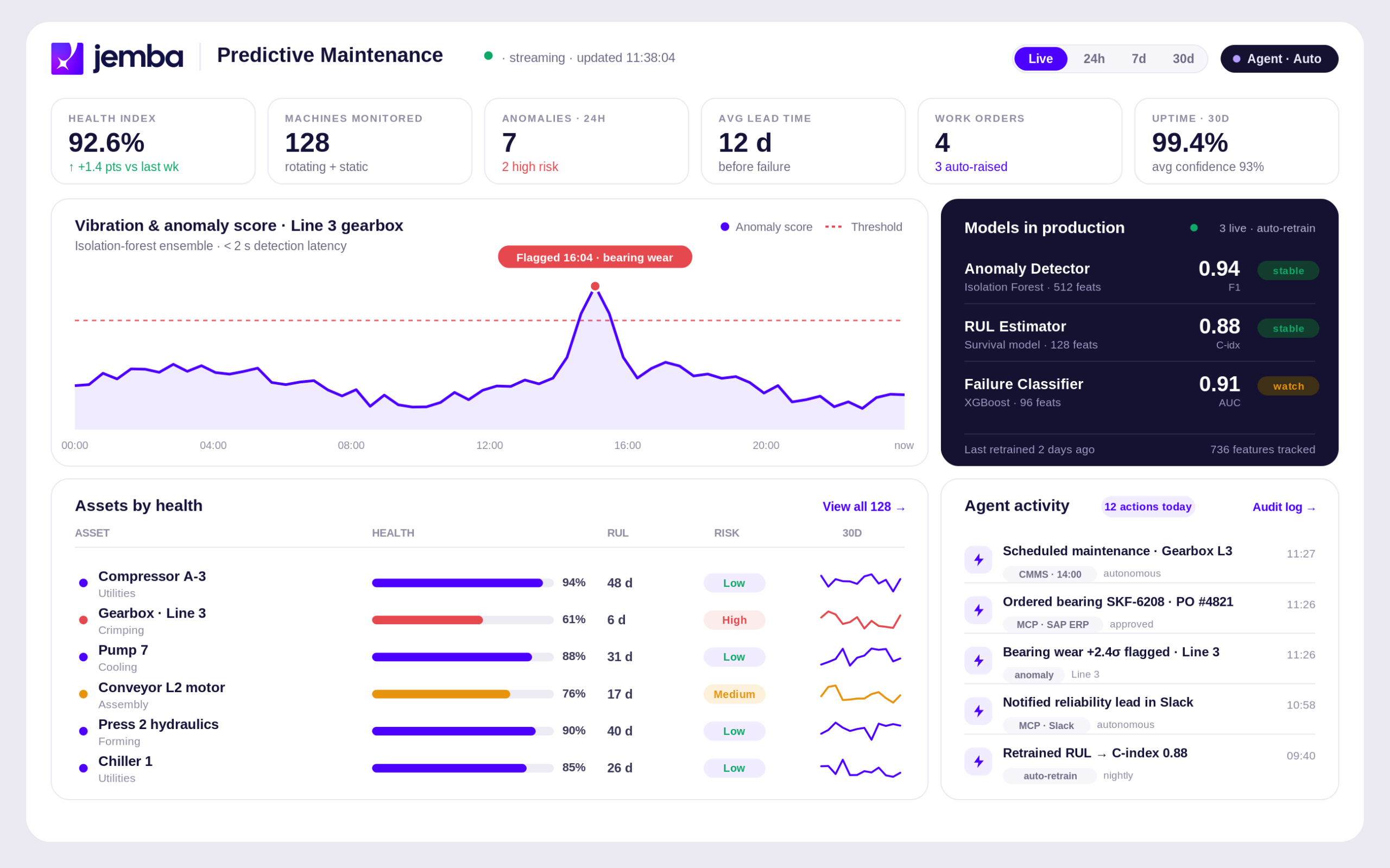
Roulements, engrenages, accouplements, pompes, ventilateurs : la signature vibratoire change avant la panne mécanique. Le ML capture les motifs subtils invisibles aux analyses spectrales classiques. Détection typique : plusieurs jours avant la défaillance.
2. Dérives thermiques
Surchauffe de moteurs, dérive de température de lubrifiant, montée anormale sur circuits hydrauliques. La détection ML capture les évolutions lentes sur plusieurs heures, qu’un seuil fixe ne signalerait que trop tard.
3. Anomalies de consommation énergétique
Une augmentation anormale de la consommation électrique d’un équipement est un indicateur précoce d’usure, de mauvais réglage ou de dégradation. Le ML détecte ces dérives par rapport au profil de consommation normal pour chaque régime de fonctionnement.
4. Instabilités process
Variations anormales de pression, débit, cadence, ou paramètres de réglage. Particulièrement utile sur les process continus (chimie, agroalimentaire de procédé, pharma) où une instabilité précoce annonce une dérive qualité imminente.
5. Anomalies multi-variables corrélées
Le type le plus puissant : aucune variable ne sort de ses limites individuelles, mais leur combinaison à cet instant précis n’a aucun précédent dans l’historique. Ces anomalies, invisibles aux méthodes classiques, sont identifiées par le ML en quelques secondes.
Le cas concret : détection anomalies temps réel sur 12 lignes de production
L’illustration la plus complète de la détection anomalies temps réel industrie par JEMBA reste le déploiement chez un équipementier automobile rang 1 français. Sur 12 lignes générant plus de 700 variables chacune, la plateforme a été déployée pour détecter en temps réel les anomalies process précédant les arrêts non planifiés et les défauts qualité.
Résultats consolidés sur 6 mois
- Détection précoce des anomalies de vibration sur les machines critiques, en moyenne 48 heures avant la défaillance
- Identification automatique des combinaisons de variables précédant systématiquement les rebuts qualité
- Réduction de 35 pour cent des arrêts non planifiés
- Économie consolidée de plus de 2 millions d’euros la première année sur 12 lignes
La détection d’anomalies temps réel JEMBA nous prévient des arrêts en moyenne 48 heures avant la panne. Nous intervenons quand c’est planifié, plus jamais en urgence.
— Responsable Maintenance, équipementier automobile rang 1, France
Plus d’exemples dans nos études de cas industrielles.
Comment déployer la détection anomalies temps réel sans data scientist
La méthode JEMBA en 4 étapes pour mettre en place une détection d’anomalies temps réel opérationnelle :
Étape A — Identifier les équipements et process critiques (semaine 1)
Cartographiez les équipements dont les arrêts coûtent cher ou dont les anomalies impactent fortement la qualité. Concentrez-vous sur 3 à 5 équipements prioritaires en première vague.
Étape B — Connecter les sources de données (semaines 1-2)
Brancher les capteurs vibratoires, sondes thermiques, compteurs énergétiques, paramètres process via historian, SCADA, MES ou flux temps réel TeepTrak. Aucun développement custom requis.
Étape C — Entraîner le modèle sur le comportement normal (semaines 2-4)
Le modèle JEMBA apprend automatiquement la signature normale de chaque équipement à partir de 3 à 6 mois d’historique. Il identifie les motifs cycliques, les transitions de régime, et les corrélations multi-variables qui définissent la normalité.
Étape D — Activation des alertes temps réel (semaines 4-12)
Les alertes sont remontées aux équipes de maintenance et de production avec des recommandations en langage métier. Phase d’ajustement des seuils de sensibilité, d’intégration aux GMAO existantes, et de formation légère des équipes.
Délai total : 8 à 12 semaines pour un premier équipement en production. 18 semaines pour un déploiement complet sur l’ensemble d’un site.
Les 5 conditions pour réussir un projet de détection anomalies temps réel industrie
- Une infrastructure capteurs minimale — vibrations, températures, courants électriques, paramètres process. Pas besoin d’un déploiement massif initial : commencez avec l’existant.
- Un historique de 3 à 6 mois — le ML a besoin de voir suffisamment de cycles normaux pour apprendre les motifs représentatifs.
- Un sponsor opérationnel — un responsable maintenance ou production qui porte le projet et associe ses équipes dès le démarrage.
- Une intégration aux workflows existants — les alertes doivent arriver dans la GMAO, le système d’astreinte, ou le tableau de bord opérateur. Pas un énième écran isolé.
- Une boucle de feedback opérateur — chaque alerte doit pouvoir être qualifiée par l’opérateur (pertinente, fausse alerte, déjà traitée). Cette boucle améliore continuellement la qualité des détections.
Les 4 erreurs à éviter dans un projet de détection anomalies temps réel
- Vouloir détecter toutes les anomalies dès le départ — commencez par les anomalies les plus coûteuses sur 3 à 5 équipements critiques. La montée en charge viendra ensuite.
- Sous-estimer l’importance des faux positifs — une plateforme qui crie au loup en permanence sera ignorée. La qualité prime sur la quantité d’alertes.
- Ignorer la formation des équipes terrain — même no-code, la détection ML demande un changement de réflexes opérationnels. Prévoir l’accompagnement.
- Mesurer la performance technique sans mesurer le ROI — un modèle à 99,7 pour cent de détection ne sert à rien si les alertes ne génèrent pas d’actions correctives mesurables.
L’impact stratégique de la détection anomalies temps réel
Au-delà des gains opérationnels directs, la détection anomalies temps réel industrie transforme la culture maintenance et qualité d’une usine. Cinq évolutions notables :
- Passage du curatif au prédictif — les interventions deviennent planifiées au lieu d’être subies
- Réduction du stress opérationnel — moins d’urgences, plus de sérénité dans le pilotage
- Allongement de la durée de vie des équipements — détection précoce des dégradations
- Amélioration de la qualité produit — anticipation des dérives avant le défaut
- Capitalisation continue du savoir — chaque détection enrichit la connaissance du système
Conclusion : la détection anomalies temps réel industrie, un standard 2026
La détection anomalies temps réel industrie par machine learning n’est plus un projet d’avant-garde réservé aux grands groupes. Avec un taux de détection consolidé de 99,7 pour cent, une réduction moyenne de 35 pour cent des arrêts non planifiés et un ROI moyen de 2,7 fois en année 1, c’est devenu un standard de performance attendu sur les sites industriels modernes.
L’accessibilité des plateformes verticales no-code comme JEMBA rend cette technologie disponible à toute usine, sans recruter de data scientist et avec des résultats mesurables en moins de 12 semaines. Pour évaluer le potentiel sur vos propres équipements critiques, le meilleur point de départ reste une démo sur vos données réelles de production.
See Jemba on your own data
A 30-minute session with a product specialist. No data scientist required, 48-hour setup.