
Corrélation Qualité par Machine Learning : Comment Identifier les Vraies Causes de vos Défauts Production
Corrélation Qualité Machine Learning : Comment Identifier les Vraies Causes de vos Défauts Production
La corrélation qualité machine learning est devenue l’un des cas d’usage les plus rentables du ML industriel en 2026. La raison est simple : dans la majorité des sites de production, le coût annuel des rebuts, retouches et non-conformités représente 2 à 8 pour cent du chiffre d’affaires — un gisement d’économies massif que les approches qualité traditionnelles ne savent pas pleinement adresser.
Les méthodes classiques — cartes de contrôle SPC, AMDEC, Six Sigma, plans d’expérience — sont précieuses, mais elles atteignent leurs limites face à la complexité des process modernes : multiplication des variables, interactions non-linéaires, dérives lentes, effets cumulatifs. Le machine learning permet de franchir cette limite en croisant simultanément des centaines de paramètres procédé avec les résultats qualité, révélant les corrélations cachées que l’analyse manuelle ne peut détecter.
Cet article explique comment fonctionne la corrélation qualité machine learning, quels résultats concrets en attendre, et comment la déployer dans votre usine sans data scientist — avec des résultats mesurables en moins de 4 semaines.
Pourquoi la corrélation qualité machine learning surpasse les méthodes traditionnelles
Les approches qualité classiques reposent sur une hypothèse simplificatrice : chaque défaut a une cause unique identifiable par l’analyse séquentielle des paramètres procédé. Cette hypothèse fonctionne pour les défauts simples, mais devient fausse dans la majorité des cas réels où :
- Les défauts résultent de combinaisons de variables — un défaut peut n’apparaître que lorsque la température est élevée ET l’humidité basse ET la cadence supérieure à un seuil. Aucune variable, isolément, n’explique le défaut.
- Les relations sont non-linéaires — augmenter une variable peut être bénéfique jusqu’à un seuil, puis devenir nuisible. Les analyses statistiques linéaires manquent ces transitions.
- Les effets sont décalés dans le temps — un défaut sur le produit final peut résulter d’un paramètre process qui a dérivé 2 heures plus tôt en amont de la ligne.
- Les interactions varient selon le contexte — un même couple de variables peut être bénin avec une matière première, problématique avec une autre.
La corrélation qualité machine learning excelle précisément sur ces quatre dimensions. Les algorithmes ML modernes capturent les interactions non-linéaires, intègrent les décalages temporels, et adaptent leur lecture au contexte. C’est pourquoi le ML révèle systématiquement des causes racines invisibles aux méthodes classiques.
Comment fonctionne la corrélation qualité par machine learning
Étape 1 — Croiser paramètres procédé et résultats qualité
Le ML compile l’ensemble des paramètres procédé mesurés (températures, pressions, vibrations, cadences, paramètres machines, conditions environnementales) avec les résultats qualité correspondants (conformité, dimensions, défauts, classes de qualité). L’objectif est de comprendre quelle configuration de paramètres procédé produit quelle qualité.
Étape 2 — Apprentissage automatique des corrélations
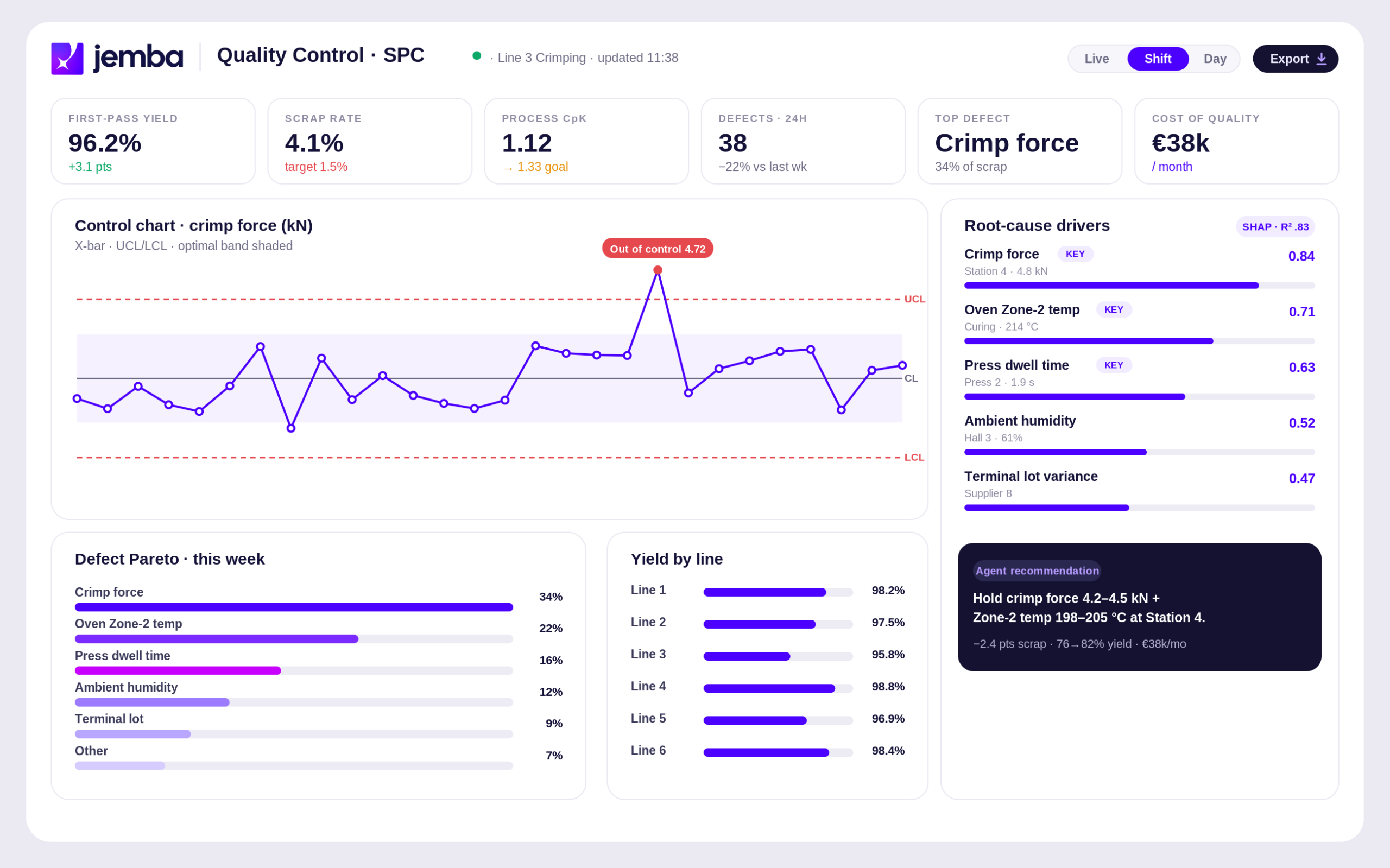
Le modèle teste automatiquement des milliers de combinaisons de variables. Il identifie les signatures procédé associées aux défauts et aux pièces conformes. Sur les déploiements JEMBA, le taux de détection ML atteint 99,7 pour cent, avec des temps de réponse inférieurs à 2 secondes.
Étape 3 — Restitution en langage métier
Les corrélations identifiées sont restituées non pas en jargon statistique, mais en langage opérationnel : « Les défauts d’aspect surface sont fortement corrélés à un dépassement de la température de cuisson au-dessus de 187 degrés pendant plus de 90 secondes, en combinaison avec une humidité matière première supérieure à 12 pour cent. » Cette restitution métier permet l’adoption immédiate par les équipes qualité.
Étape 4 — Recommandations actionnables et alertes temps réel
Le modèle ML déployé en production génère des alertes temps réel dès que la combinaison de paramètres à risque est détectée. L’opérateur peut alors corriger avant la production du défaut, plutôt que de constater le rebut a posteriori. Découvrez l’interface de cette logique sur la plateforme JEMBA.
Les résultats mesurés de la corrélation qualité machine learning
Sur les 360+ déploiements industriels JEMBA, les indicateurs consolidés de corrélation qualité machine learning sont les suivants :
- Moins 22 pour cent de rebuts et retouches en moyenne
- Réduction des contrôles destructifs de 30 à 50 pour cent
- Détection précoce des dérives qualité, parfois plusieurs heures avant la production du défaut
- Pay-back moyen inférieur à 6 mois
- ROI année 1 typique de 3 à 6 fois sur ce cas d’usage
Ces indicateurs varient selon les secteurs : en agroalimentaire, le gain principal porte sur la conformité dimensionnelle et la stabilité des recettes ; en automobile, sur les défauts d’aspect et de dimension ; en pharma, sur la conformité aux spécifications de pureté ; en électronique, sur la précision des assemblages.
Le cas concret : passer de la mesure de la qualité à sa maîtrise causale
Le meilleur exemple de l’impact de la corrélation qualité machine learning reste le cas phare JEMBA chez un équipementier automobile rang 1 français. Sur 12 lignes de production, l’équipe qualité contrôlait scrupuleusement les paramètres et constatait les défauts — sans réussir à identifier leurs causes racines malgré plusieurs années d’efforts.
L’approche avant JEMBA
- Contrôles qualité destructifs sur des échantillons
- Cartes de contrôle SPC sur les paramètres procédé principaux
- Analyses 5M et AMDEC périodiques
- Plans d’expérience occasionnels sur les paramètres suspectés
- Rendement bloqué autour de 30 pour cent depuis plusieurs années
L’approche avec JEMBA
- Analyse simultanée de 700 variables procédé sur 6 mois d’historique
- Identification de 10 paramètres clés expliquant 83 pour cent des défauts
- Mise en évidence de 4 leviers actionnables par les équipes terrain
- Alertes temps réel sur les combinaisons à risque
- Rendement passé de 30 à 80 pour cent sur la ligne pilote
- Plus de 2 millions d’euros économisés la première année
La corrélation qualité ML a révélé des causes que nous avions cherchées pendant des années. Quatre paramètres, pas deux cents. Nous avons enfin compris pourquoi nos défauts apparaissaient.
— Directeur Qualité, équipementier automobile rang 1, France
Plus de détails dans nos études de cas industrielles.
Les 5 cas d’usage prioritaires de la corrélation qualité machine learning
1. Identification des causes racines de défauts récurrents
Pour les défauts qui apparaissent sporadiquement sans cause claire identifiée par les analyses classiques, le ML révèle les combinaisons de paramètres responsables. C’est le cas d’usage le plus rentable, particulièrement quand le défaut coûte cher.
2. Prédiction du taux de conformité en sortie de ligne
Anticiper, dès l’amont du process, la qualité du produit fini. Permet d’ajuster les paramètres avant qu’un défaut ne soit produit. Particulièrement précieux sur les process longs (chimie, agroalimentaire de procédé, pharma).
3. Réduction des contrôles destructifs
Quand le ML prédit avec haute fiabilité la qualité finale à partir des paramètres procédé, il devient possible de réduire les contrôles destructifs aléatoires. Gain typique : 30 à 50 pour cent de réduction des contrôles destructifs sans dégradation de la qualité livrée.
4. Adaptation automatique aux variations matières premières
Dans les secteurs sensibles à la variabilité matière (agroalimentaire, chimie, plasturgie), le ML identifie comment les paramètres procédé doivent être ajustés en fonction des caractéristiques de la matière entrante.
5. Capitalisation du savoir-faire opérateurs experts
Les meilleurs opérateurs ajustent intuitivement les paramètres en fonction du contexte. Le ML capture leurs ajustements implicites et les rend disponibles à toute l’équipe — y compris pour les nouveaux arrivants.
Les 6 erreurs à éviter dans un projet de corrélation qualité machine learning
- Limiter l’analyse aux paramètres déjà suspectés — laissez le ML découvrir les corrélations inattendues. Les meilleures découvertes viennent souvent de variables que personne n’avait priorisées.
- Sous-estimer la qualité des données qualité — si vos résultats qualité sont mal horodatés, mal référencés ou incomplets, le ML ne pourra pas faire de miracles. Auditez les données qualité avant le déploiement.
- Vouloir tout corréler en une seule analyse — concentrez-vous d’abord sur un type de défaut prioritaire. La sur-globalisation dilue les corrélations.
- Confondre corrélation et causalité — le ML révèle des corrélations statistiques. La causalité doit être validée par l’expertise métier et, idéalement, par des essais contrôlés.
- Négliger l’intégration aux workflows opérationnels — une corrélation qualité identifiée mais non intégrée aux alertes temps réel ne génère qu’une fraction de sa valeur potentielle.
- Oublier de mesurer l’adoption — vérifier régulièrement que les recommandations ML sont effectivement suivies par les équipes terrain. Une plateforme à 99,7 pour cent de détection utilisée par 30 pour cent des équipes ne produit que 30 pour cent du ROI attendu.
Comment déployer la corrélation qualité machine learning dans votre usine
La méthode JEMBA en 4 étapes pour un projet de corrélation qualité ML :
Étape A — Définir le défaut prioritaire (semaine 1)
Choisir le type de défaut le plus coûteux ou le plus problématique pour démarrer. Mesurer la baseline actuelle : taux de défauts, coût annuel des rebuts, coût des retouches.
Étape B — Collecter données procédé et qualité (semaines 1-2)
Brancher l’historian, le SCADA, le LIMS et les bases de données qualité. Vérifier la cohérence temporelle entre paramètres procédé et résultats qualité.
Étape C — Entraîner le modèle de corrélation qualité (semaines 2-4)
Le modèle ML s’entraîne automatiquement sur l’historique. Il identifie les paramètres et combinaisons de paramètres les plus prédictifs des défauts. La restitution est faite en langage métier compréhensible par l’équipe qualité.
Étape D — Déploiement en production et alertes temps réel (semaines 4-12)
Mise en place des alertes opérationnelles sur les combinaisons à risque. Formation des équipes. Mesure du gain sur le taux de défauts. Itération sur les seuils d’alerte.
Délai total typique : 8 à 12 semaines pour un premier cas d’usage de corrélation qualité ML opérationnel. Sans recruter de data scientist.
Conclusion : la corrélation qualité machine learning, un standard de performance 2026
La corrélation qualité machine learning n’est plus une technologie exploratoire : c’est aujourd’hui un standard de performance attendu sur les sites industriels modernes. Les chiffres consolidés sur 360+ déploiements (moins 22 pour cent de rebuts, ROI de 3 à 6 fois en année 1, pay-back inférieur à 6 mois) en font l’un des leviers d’amélioration continue les plus rentables disponibles.
Cette puissance est désormais accessible à toute usine grâce aux plateformes ML verticales no-code comme JEMBA, sans recruter de data scientist et avec des résultats mesurables en moins de 4 semaines. Pour évaluer le potentiel sur vos propres défauts, le meilleur point de départ reste une démo sur vos données réelles.
See Jemba on your own data
A 30-minute session with a product specialist. No data scientist required, 48-hour setup.